
In 2011, a hero to so many of us including myself was in the last stages of pancreatic cancer. Steve Jobs, an icon of the PC revolution, and later what should rightfully be called “the mobile revolution”, was working hand in hand with author Walter Isaacson. The pair were completing the last biography he would take part in while alive.
The book, simply called Steve Jobs, was published 19 days after Jobs’ death and quickly rose to bestseller status. The book contains many memorable tales about the way he motivated others. In one often referenced experience, we read about Jobs driving home the point that making computers faster can save entire human lifetimes.

Now, 35 years since related by Steve Jobs in August 1983, we can plainly see that the math behind his dramatic example was wrong … but maybe that’s okay.
Jobs was not an engineer. He was also not the original inventor of many ideas which made Apple’s products a game changer. Like many successful visionaries, his value to the market — and to the world — was his ability to help others connect the dots.
In leading Apple, he created narratives that captured imaginations and provided motivation. His famous ‘reality distortion field’ worked because he showed his employees things they wanted to believe. He packaged goals as a better reality than the one his audience existed in moments before.
People forgot about preconceived limits. As perceptions and desires outstripped current reality, his engineers and product designers were doggedly motivated to close the gap — by improving actual reality.
In the final biography, Isaacson relates the particular moment which inspired many including the team at my company Pocketmath. Jobs had always championed the quality of the user’s experience, and one day he set his sights on the onerously slow boot time common to computers of the era.
According to Isaacson, the Apple CEO explained to engineer Larry Kenyon what dramatic impact 10 seconds of boot time savings would have:
“Jobs went to a whiteboard and showed that if there were five million people using the Mac, and it took ten seconds extra to turn it on every day, that added up to three hundred million or so hours per year … [sic] … equivalent of at least one hundred lifetimes saved per year.”
The story sounds great, and we have no reason to doubt Jobs really delivered such a message. Furthermore, it likely did have a profound effect. Isaacson later writes that Kenyon produced boot times a full 28 seconds faster.
However, the math doesn’t add up. Based on the assumptions outlined, it saves far less than 100 lifetimes.
In the 2005 book Revolution in the Valley: The Insanely Great Story of How the Mac Was Made, author Andy Hertzfeld quotes Steve Jobs somewhat differently:
“Well, let’s say you can shave 10 seconds off the boot time. Multiply that by 5 million users and that’s 50 million seconds every single day. Over a year, that’s probably dozens of lifetimes. Just think about it. If you could make it boot 10 seconds faster, you’ll save a dozen lives. That’s really worth it, don’t you think?”
Let’s walk through the math.
Assume, just as Jobs did, that there would be 5 million people using the Mac. Likewise, assume the time savings is 10 seconds each day per person. Each day, 50 million seconds are saved. In a year, that translates to a savings of 50 million multiplied by 365 days which is 18.25 billion seconds.
Let’s translate that savings into hours. There are 60 seconds in a minute and 60 minutes in an hour. So, there are 60 times 60 which is 3,600 seconds in an hour. To obtain the number of hours saved, divide 18.25 billion seconds by 3,600 seconds. The result is 5,069,444 hours of savings.

Now, let’s compute a typical life span of 75 years in hours. We calculate 365 days per year times 24 hours per day times 75 years. The result is 657,000 hours.
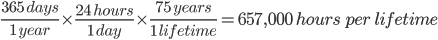
So, how many lifetimes have we saved? We divide the total savings 5,069,444 hours by our assumed typical lifespan of 657,000 hours. We have saved nearly 8 lifetimes.

Of course, it’s unlikely Jobs was trying to make his point in anything but rough numbers, but his 100 lifetimes or even dozens is dramatically off — by about an order of magnitude.
Did Jobs goof on the math? Was he misquoted?
Maybe it doesn’t matter. Jobs made a point that some relatively small amount of engineering effort would save lifetimes of time, and he was right.
What’s more, the power of the lesson — even if flawed — paid bigger dividends. Apple not long ago became the world’s first trillion dollar company, and the company sold 3.7 million Mac computers in Q3 of this year alone. With many Macs remaining in service for several years, there are quite likely a lot more than 5 million people using a Mac at the very moment you read this.
The story itself has been quoted profusely since appearing in Hertzfeld and Isaacson’s works. Are we going to lambast the story as “fake news”, or are we going to say that everyone makes mistakes but the basic idea was right? One thing is possibly true: if anybody checked the math, they didn’t talk about it.
For what it’s worth, I’ll hazard a guess where the original math went wrong. Suppose we convert 18.25 billion seconds saved into hours by dividing by 60 seconds in the minute and then another 60 minutes in the hour. Now, suppose while scribbling on the whiteboard Jobs only divided by 60 one time. We get 304,166,167 — about 300 million, the number quoted in the book. That would be correct if were were talking about the number of minutes, not hours.
Yet again, we’ve seen the reality distortion field in full effect. During 13 years since publication, the story has been read by millions. It has been enthusiastically retold without question in Isaacson’s biography, well known periodicals including the Harvard Business Review and throughout the web and social media.
It’s worthwhile to note that Apple’s operating system has changed drastically since the 1980’s. Apple’s OS X desktop operating system launched in 2001 replaced core components with those borrowed from BSD, an operating system of UNIX roots. As such, it’s likely the optimizations built in 1983 at Jobs’ urging have long been outmoded or removed entirely.
However, the operating system has continued to evolve upon its past and take inspiration from those stories. More broadly, Apple as a business would not be where it is today had it not had some degree of early success. Each product in the technology world builds on lessons and customer traction gained from previous versions.
One can argue not all technological progress benefits people, but I find it difficult to say there haven’t been some home runs for the better.
While reality may have been distorted longer than many would have dreamed, reality also caught up. As Apple made its reality catch up, its products have contributed lifetimes to the human experience. And … maybe, just maybe … there was some “fake it ‘til you make it.”
